Sppmacd's Blog
Storage Engine for EssaDB
Jan 21, 2023Every database engine needs a storage to actually be a database engine. As I’m creating a database engine, I thought that it would be nice to implement it some time. This is how it works. Maybe it will help somebody understand how databases work, even if my implementation is probably the worst possible way to do this.
What is EssaDB anyway?
EssaDB is a custom, (almost) from-scratch1 SQL database engine written in C++.
1 the only dependency for the engine is currently fmt, and SDL for GUI.
But why?
Everything started somewhere in September 2021, when we had first “database laboratory” lessons. And we started with… Microsoft Access.
As you probably know, MS Access is a part of MS Office package. It was intended to be easy to use for people that don’t know databases that much - you can create queries, forms and reports, all from the GUI. It sounds like a nice idea. Theoretically.
The reality is, that it is very easy to make things going wrong. For example:
- Access will probably crash when you open a database that was created on a system that has set a different language than the system you are currently on.
- There is NO syntax highlighting or even fixed-width font AT ALL in a SQL editor:

- You can write your queries in SQL, but if you make an error, it’s hard to get back to the editor, because Access opens a “table” view by default. And making an error isn’t that hard, provided Access has at least “inconsistent” support for aliases.
- Importing “works”. Sometimes.
I’m not even saying that it is only for Windows. OK, enough rant for now. Let’s talk about storage!
How does this work?
Every database is stored in a separate directory. Currently it contains a single file for every table. This file is called an EDB file (an acronym from Essa DataBase).
The file consists of a main header and blocks. Every block stores type (free, table, heap or big), previous and next block index and data space for 255 rows. As you can see, this is something like doubly-linked list; pointers to first and last block of each type are stored in a main header.
Block types
There are 4 types of blocks:
- Free: Store nothing. They are created after freeing data. Currently this is not possible as freeing blocks is not implemented.
- Table: Store rows, and how much rows are in this block (That’s why a block can fit 255 “row slots”, because this “how much” value is a
u8with a maximum of255.) - Heap: Store variable-sized data. We will talk about this later.
- Big: Store big chunks of data that don’t fit a single block. This is currently not implemented.
Row slots
Rows are stored in Table blocks with a linked list like structure, so that we can remove them in constant time.
Every row slot is:
- a pointer to the next row (null if this is a last row)
- whether a row is “used” (that is, something is stored there)
- actual row data. We ensure that every row is of constant size, so that we can allocate them efficiently - all variable-sized data is stored on heap.
Problems
There are some problems that we need to solve when we want to store very big amount of data:
- We can’t just load the whole table to memory, as it may take a bunch of gigabytes.
- It needs to handle insertions, deletions and structure changes.
- You must be able to insert variable-sized data (like varchars) to it.
Not loading everything to memory
The first problem seems easy: currently we just mmap the whole table file. This allows us to read databases (almost) as they would be on memory, but for VERY big files, it requires having a 64-bit system (which is not a problem today, I think).
But there is another problem with that: memory alignment. In the file, we want data to be packed as much as possible, but it happens that some (most) CPUs don’t like reading data that is not size-aligned. That is if you want to read 4 bytes, the address must be divisible by 4, otherwise the program will crash or at least slow down (as for x86). I come up with a solution for that - a RAII class that reads unaligned data to a temporary buffer, makes its user perform all operations on this buffer, and then copies data back to the original buffer on destruction.
This is how it looks like:
{
// Read a header from unaligned memory at `header_ptr`.
AlignedAccess<Header> header { header_ptr };
// Read some field.
m_some_field = header->some_field;
// Perform operations on a temporary buffer, everything aligned.
header->some_other_field = 2137;
// Methods should work as expected.
header->do_something();
}
// On destruction, AlignedAccess ensures that the modifications were written.
There are obviously disadvantages. For example, you need to copy data back and forth. Also, if you have two AlignedAccess objects that point to the same place, they will “fight” for which data will be written.
{
// Read a header
AlignedAccess<Header> header1;
// In some function...
{
AlignedAccess<Header> header2;
header->do_something_expensive();
}
}
// "Something expensive" is lost, because it is overridden by `header1`'s buffer.
To solve this problem, I added some additional functions:
flush()so that you can explicitly write back the dataclear()so that you can indicate you don’t want data to be written back anymore.
Unfortunately I did not find a way to statically check for these kinds of errors, so you just need to avoid calling functions that perform complicated operations on data while having an AlignedAccess object created. Anyway, this is still better than reading and aligning everything manually I think.
Handling all the operations
This is possible because of the linked-list structure of the file. So, let’s assume we start with something like this:
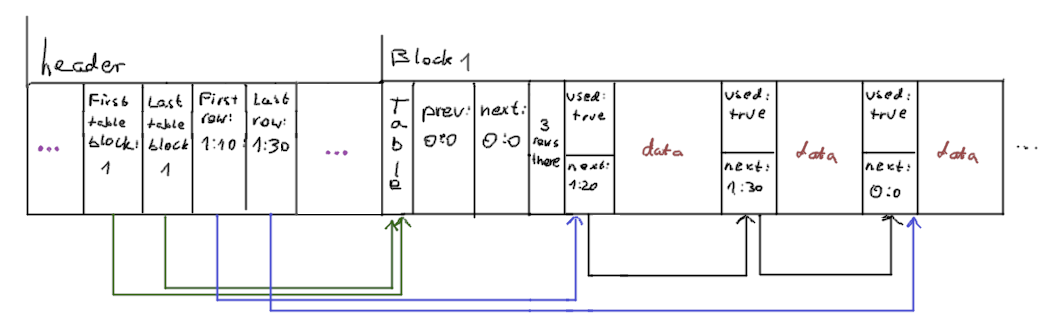
Or in a simpler way:
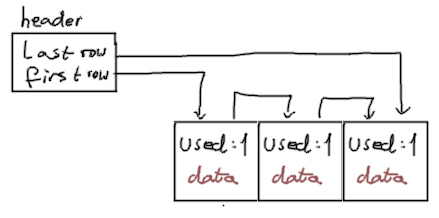
Here we have 3 rows in a single block, stored contiguously.
Iterating
This is pretty straightforward; you just start from the first row (defined in main header) and follow next-row pointer until it is null. We only need to remember previous row, so that we can point it to the next row on removal.
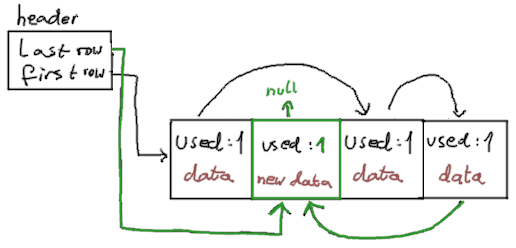
Inserting
If we wanted to insert a new row:
- We iterate on blocks to find a first block that has some space in there. We can just check if a block is of type Free or if it is of type Table and has less than 255 rows. This is the most expensive operation.
- In a eligible block, we need to find some space for allocation. We can just simply iterate over 255 slots and find out if something is there.
- If we found a space, we can write data.
- If not, we need to allocate a new block.
- We always insert at the end, so we need to point a row that was previously the last, and a header, into our new row.
- We also update row count in a header.
After all these operations, our file will look like this:
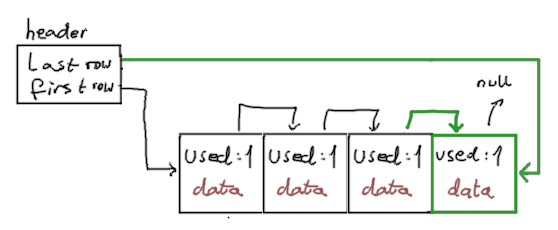
Note that we changed “last row” in header and “next” in 3rd row slot.
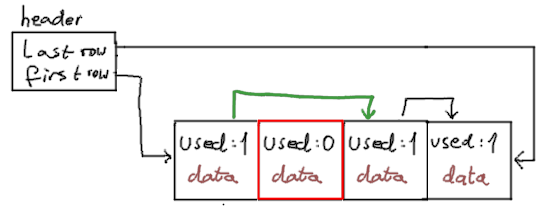
Deleting
This is much simpler:
- Iterate to 2-nd row, remembering pointer to it and to previous row.
- Mark it as unused, and free associated heap data
- Point that previous row to next row, or to null if we are removing last row
- Update block row count and headers.
If we wanted to remove a second row2, this will look like this:
We can now try to insert once more; a previously freed slot will be reused (This becomes a bit complicated now):
Changing structure
What if we wanted to add or remove a column? We do it in a bit hacky and inefficient way, but I could’t come up with anything better: we just rename table to table__BACKUP<time>, drop table, recreate table with a new structure, and copy all rows from backup table to a new table, handling NOT NULL, not matching columns and other annoying errors there3. Then we should remove the backup table, but we aren’t doing that. Why? Because of laziness.
2 Note that there is no random-access. I just need to refer to that row in some way.
3 When I was writing it, I realized that we don’t rollback changes when this kind of error occurs… This is an issue for later.
Variable-sized data
For data that may be variable size, we just store a HeapSpan (pointer and size) to a heap-allocated data. This heap uses a free store implementation, which I will explain in detail in another post - this becomes too long already (It’s also just kind of pretty dumb linked list thingy for now).
Limitations
- Block allocation is not implemented. This means that only a single block (255 rows) can be written, and heap space is also limited. This makes EDB unusable for most applications.
- EDB doesn’t support indexes, constraints, checks and other advanced SQL features (yet!).
- Insertion is not constant time. I think this can be done by storing a place that is known to be free, but I didn’t investigate this further.
Summary
As you can see, this format is not great and needs many tweaks. For now, we don’t care about backwards compatibility so we can add or remove fields to the header, for example.
If you weren’t bored by this article and you have read it in the whole, thanks and until next time!